行业动态
浅谈平均处理时长预测参数在人员配备中的计算

呼叫中心行业是人员流动性较强的行业,坐席代表流动频繁的问题是存在且现实的,在此基础上,为了保障其顾客满意度,对资源统筹就提出了更高的要求。这个要求可以理解为,现实存在的情况就要求在做资源统筹时,支撑做长期人员配备的各项预测参数(包含业务量、效率、耗损、占用率等)尽量准确,本文想在实际应用中的平均处理时长的预测数据做一下简单的探讨:
前期在做员工平均处理时长的数据预测时,方法较为单一化,一般是直接使用历史数据做均值即可,而历史数据要使用多长的历史周期,是没有明确的规定的,看对该业务实际情况的了解情况来判定,无批量的新员工加入干扰或短时间内预测准确率在正确的范围区间内,都可加入均值取数的周期内,这种预测的方法较为粗狂且无可定义的方法,完全依据于对业务的了解程度;
使用一段周期后,加入了对数据的离散度的考虑,即添加计离散数据的方法,比如目前在使用的VSF波动分析,使用历史12周的数据看VSF波动系数,当VSF波动系数<0.7的时候,我们就认为这个业务的AHT波动较小,历史的数据直接取用其平均值就可以;当VSF波动系数>0.7时,判需要看具体是哪一周的加入,开始导致VSF波动系数增大,加入的那一周会抛出不做时候用;这种方法在一定程度上较第一种的考虑会更有逻辑方法话,但也有一定的弊端,以上的考虑并没有顾及到的问题就是,新员工的加入对AHT的影响没有做留存和记录,即没有足够的数据可以证明这个业务新员工的进入撤离计划对业务的影响是平稳的。
基于此种情况的考虑,目前的使用方式一般是两种,一是可以继续使用历史十二周的平均值(加入考虑周期波动的观测),同时需要留存新老员工的配比数据,即新人进入的计划和实际进入是否按计划开展,影响数据进行量化展示;另一种方法就是,使用每批次人员的人数和人员成长曲线中达成的数据做权重取值,但是其预测准确度也是会监管,当预测准确度偏离准确区间时,分析原因并做留存;
针对使用每批次的员工人数和人员成长曲线中达成数据做权重取值的方法中,原先在使用的时候,是依据各批次的人数和批次人员达成的AHT相乘,再除以总人数测量得出,即使用人数的占比测算,后来在验证中,发现这种方法测算出来的员工的承接能力不对等的,怎么理解呢?以A业务为例,我们举一个简单的例子,做个计算题看看,其团队规模为100人,其中新员工人数为30人,成长曲线中对应时间内的AHT达成应451.76s,成熟员工为70人,成长曲线中对应时间内的AHT为325.00s,新、成熟员工的工作时长均为8小时,占用率85%的情况下,分别计算其承接能力,新员工的承接能力结果为1626单,成熟员工的承接能力结果为5273单,合计承接能力为6898单(如表a1);若新、成熟员工的AHT数据按人数取权重后,得出AHT是363.03s(计算公式:(451.76*30+325.0*70)/100),在同样的时长8小时,占用率85%的情况下,得出的承接能力为6743单(如表b1),承接能力的结果数据显示,比分别计算出的承接能力后再求和低155单,这就意味着,如果单一的使用人数的权重来计量AHT时,其承接能力会被过低的估量;而直接使用人数测算出平均处理时长后再计算其承接能力的结果高于分别计算各批次员工的承接能力再求和,已论证多个不同规模,多批次的员工,结果都是一样的;
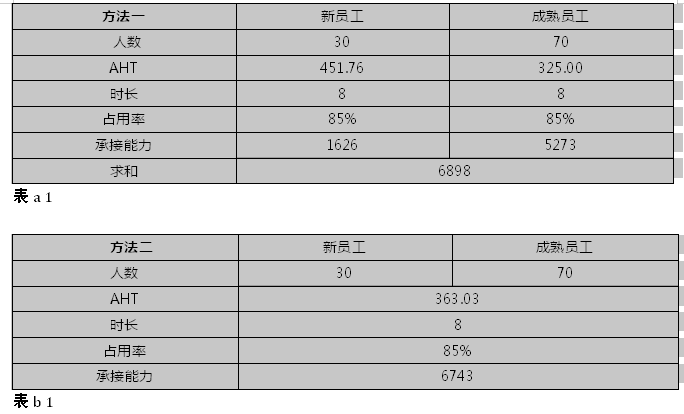
这个结果就意味着,在做长期人员配备时,无形中对人数的需求是多的,而这个情况,对于团队规模较大,弹性较大的业务来说,人数上的差异感知可能并不是很大,而对于三四十的人的小团队来讲,需求配置多2-3个人,就会出现同等话务量需求、排班方案等条件一致的情况下,其服务水平的达成会更高,人员会出现浪费的情况。不管是对于规模较大的业务,还是规模较小的业务,在人力市场如此紧张的情况下,对于人员匹配的评估偏差会直接导致其业务后期的运营保障。因此,在实际做长期的人员配备时,员工平均处理时长这个参数的预测在遇到波动较大,且批次较多的情况时,会使用承接能力的权重计量最终结果数据,而不是仅仅单一的考虑人数的权重。
人员长期配备中关于平均处理时长的预测方法多种多样,希望此文章,可以提供读者,在做效率预测时的新思路,方法很多,适合的才是最重要的。
山东澳迪赛企业管理咨询有限公司
解敏敏
解敏敏

